
So you need to get some data from Target… But are you willing to copy-paste the information by hand to an excel sheet? Hell no! You have web scraping for that!
Everywhere you virtually turn, you’re bound to run into some form of web scraping, so let’s discuss what it is. If you want to skip to another question, feel free to use the timestamps in the description below.
What is Web Scraping?
Web scraping is a way to collect data automatically. It allows gathering data from the Internet on a massive scale to extract valuable insights: product and pricing information, competitor actions, consumer sentiments, business leads, and much more.
What are the Reasons that People Scrape Target.com?
First, it’s sometimes used for market research to analyze competitor prices or features on a large scale. This is hugely beneficial for businesses that make decisions based on data.
Second, affiliate sites largely depend on Target scrapers to help them collect product data and refresh it daily. We talk about that more in this video about Price Aggregator sites.
Third, it’s often used by resellers. For example, a trending business model is to buy new retail sports cards from Target and resell them for a much higher price. Where’s the catch?
You must know the patterns when Target is doing restocks and buy the cards during a 5-minute window. That’d be very hard to do if you’re not sitting in front of your computer 24/7, so people use bots. They automatically go to Target and press buttons to buy the card. To know exactly when a restock takes place, people outfit their bots with monitors, which constantly scrape the website looking for changes.
These are just a few examples of why you’d scrape Target.com.
How to Use Parsehub to Scrape from Target.com
Ok, now let’s get down to business. What do you need to start scraping Target?Target uses Javascript, so if you’re up to doing everything on your own, you’ll need a headless browser with Selenium or Puppeteer. But if you’re more into beginner-friendly solutions, you can try scrapers like Parsehub.
To scrape an e-commerce website without coding skills, you’ll need to download a free web scraper. While a handful of web scrapers are available, we think you’ll enjoy Parsehub. It’s free and easy to use and has a suite of features we think you’ll enjoy: cloud-based scraping, IP rotation, dropbox integration, scheduling, and many more. So let’s show you how you can scrape product data from Target.

- Once Parsehub is downloaded and installed, click the ‘NEW PROJECT’ button and submit the URL you want to scrape. In this case, it’ll be kitchen items that are on sale on Target.com.
- Once the site is rendered, a select command will automatically be created. You’ll need to select the main element to this. Rename the selection to ‘SCROLL’.
- Once the main div is selected, you can add the scroll function. On the left sidebar, click on the plus sign next to the scroll selection. Click on ‘ADVANCED’. Then select the scroll function. You’ll need to tell how long the software needs to scroll. You may need a bigger number depending on how big the page is. But for now, let’s put it to two times and ensure it’s aligned to the bottom.
- Now click on the plus sign next to your page command and choose the select option. Click on the first product name on the page. Your name will become green to indicate that it’s been selected. The rest of the product names will be highlighted in yellow.
- Click on the second one on the list. Now all the items will be highlighted in green. You may need to do this twice to train Parsehub on what you want to scrape fully.
- On the left sidebar, rename your selection to PRODUCT. You’ll notice that Parsehub is now extracting each product’s name and URL.
- On the left sidebar, click the plus sign next to the product selection and choose the relative select command. Using the relative select command, click on the page’s first product name and then on its listing price. You’ll see an arrow connecting the two selections.
Repeat these steps to extract any type of data you want: the number of views, product image, sale price, and brand. We have selected all the data we want to scrape from the results page.
Now we’ll tell Parsehub to click on each product we selected and extract additional data from each page. In this case, we’ll extract the product specifications.
- First, on the left sidebar, click on the three dots next to the main template text. Rename the template to SEARCH RESULTS PAGE. Templates help Parsehub to keep different page layouts separate.
- Now use the plus sign next to the product selection and choose the click command. A pop-up will appear asking you if this link is the next page button. Click NO and input a new template name next to CREATE NEW TEMPLATE.
In this case, we’ll use PRODUCT PAGE. Parsehub will now automatically create this new template and render the target product page for the first product on the list.
- First, switch into browse mode and scroll until you see the specifications. Now click on the SHOW MORE button. Once the table has been expanded, switch browse mode off. While using the select command, click on the first element of the list. In this case, it’ll be the dimensions.
- Like we’ve done before, keep clicking on the items in the table until they all turn green. Rename the selection to SPECIFICATIONS. Your product page template should look like this. You might want to scrape several pages worth of data for this project.
So far, we are only scraping page 1 of the results page. Let’s set up Parsehub to navigate to the next 5 results page. On the left sidebar, return to the search results page template. You might also need to change the browser tab to the search page results.
- Click on the plus sign next to the page selection and select the command. Then select the next page link at the bottom of the Target page. Rename the selection to NEXT. By default, Parsehub will extract the text and URL from this link.
- To expand your new selection and remove these two extract commands. Now click on the plus sign of your next selection and choose the click command. A pop-up will appear asking if this is the next link. Click ‘YES’ and enter the number of pages you’d like to navigate to.
In this case, we’ll scrape 5 additional pages. Now that we’re done setting up the project, it’s time to run a scrape job.
On the left sidebar, click on the green ‘GET DATA’ button and the ‘RUN’ button to run your scrape. We recommend doing a test run for longer projects to verify that your data will be formatted correctly.
After completing the scrape job, you can download all the requested information as a handy spreadsheet or as a .json file.
What Can You Do If You Get Blocked?
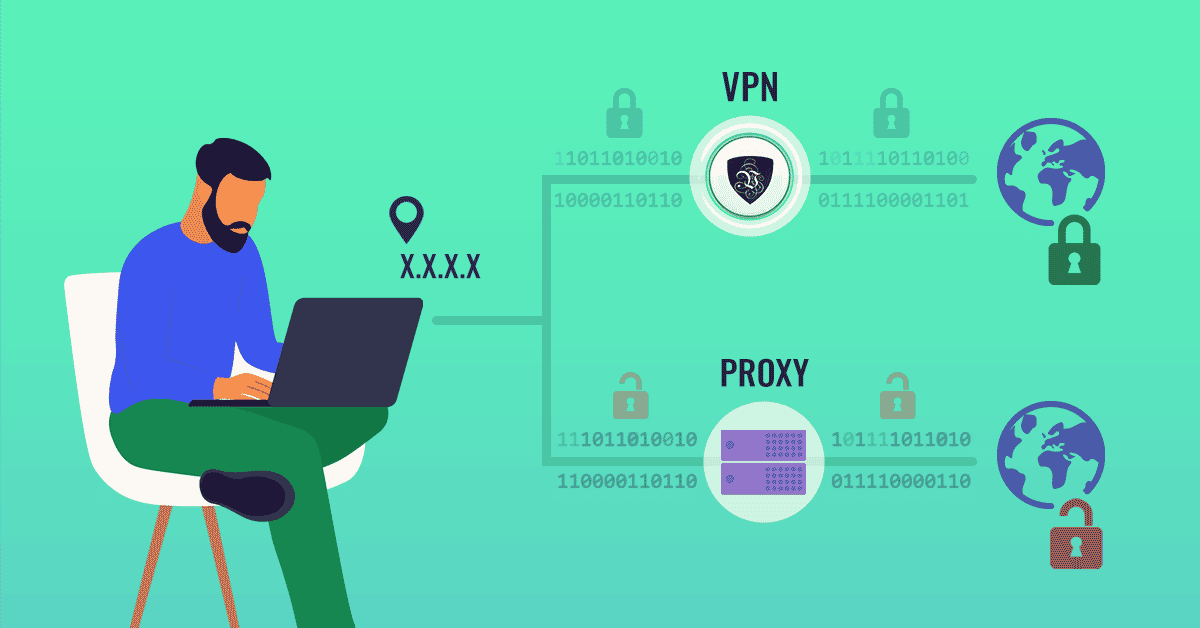
Now you’re ready to scrape. But what if you get blocked? Target hates scrapers and bots. It uses various techniques to ban bots and web scrapers as soon as it notices any suspicious activity. For example, too many requests are sent from the same IP address.
You should use proxies to hide your IP address and rotate it from time to time to avoid suspicions from Target. If you don’t know what they are, they are basically different IP addresses you can use to do tasks on the Internet on your behalf. Target will see your proxy’s IP instead of yours when you’re using a proxy. So your IP won’t get banned.
Source: Security Feed