

If you’re looking for ways to scrape the data from Google’s search result pages, then read this article. Every business professional needs a quick and easy way to scrape Google from an SEO specialist to a stock or cryptocurrency forecast expert. After all, the quality of their work depends on it. That’s why we are reviewing a promising and affordable google search results scraper SERP master.
This article will give you a tutorial on scraping Google search results with SERPMaster. You’re new to the topic. Let’s start from the basics.
About SERPs
SERP is an abbreviation of the search engine results page displayed. After you enter a query into a google search the websites, you see on these pages aren’t random or accidental. In fact, they are ranked according to the keywords used and various other factors.
Avoiding ReCaptchas
A common concern among scrapers is how to avoid ReCaptchas. ReCaptchas are security features that Google uses to verify that you are a human and not a robot. However, there are ways around ReCaptchas, and many guides can help you do it. The following are some methods to avoid ReCaptchas when scraping Google search result pages.
The first step in avoiding Captchas is to make sure your web scraping program is of high quality and backed by excellent tools. Additionally, high-quality proxies ensure your scraper works without problems for years. Remember that using public proxies or insecure scrapers will trigger Captchas. Fortunately, there are software solutions to this problem, such as ScraperAPI.
Another effective way to avoid ReCaptchas while scraping Google search result pages is to use proxies. You can use clean residential IP proxies to avoid being identified as a bot. Invisible Captchas can also trigger a 503 Service Unavailable error. By using proxies, you can avoid bot detection and avoid spamming by scraping Google search results pages.
When scraping Google search result pages, make sure you use a service that allows you to avoid the reCaptchas. Some sites offer free tools to solve CAPTCHAs, but they are very sensitive about user privacy. Besides, you need to use your own browser to get the best results from Google. This will make your scraping easier and more profitable. If you want to avoid the reCaptcha, try to make your scraping easier, and be sure to set your browser cookies before you start.
Another common method of avoiding ReCaptchas when scraping Google is to set up a proxy. A proxy acts as a third party between the web page and the user. It requests the webpage and then sends it back to the user. This prevents Google from knowing that you have made a request. It is also possible to set the referer header to appear if you have come from another page, and the same thing can be done if you want to bypass the reCAPtcha.
What is SERPMaster, and How Does It Work?

Since most people select the first search result, often completely ignoring the rest, everyone wants to rank on top. Knowing this, you can probably guess what SERPMaster is and what it does.
That’s right!! SERP API is a specialized tool designed to collect information from search engines. Organic results Ads or product information having access to this data allows SEO specialists to build their strategy of becoming more visible to potential clients.
SERPMaster works by downloading the search page and extracting the right kind of data from it that sets it. Apart from a simple web scraper, SERPMaster handles everything from proxy management to captures and data passing. All you have to do is form the right query using some of your coding knowledge and send requests to the API. If you perform this correctly, SERPMaster promises to deliver structured results with a 100 success rate.
3 Ways need to know Scrape Google Search Result Pages
Using a data collection service
One of the main challenges with Google search data scraping is its difficulty to scale. Manually gathering data on search results is time-consuming and inaccurate. Google’s algorithm uses many factors to determine the results it returns to a visitor, including the device they are using and the search query they made. The following are some steps to follow to scrape Google search data. However, remember that you need to consider the data type and amount to ensure accurate results.
To start scraping, you need to choose a data collection service. There are many options for data collection services. There are free and pay-as-you-go options. The free versions support up to 10k keyword requests per day, and you’ll have to pay more if you want to use more. Most 3rd party data scrapers charge a monthly fee, but they don’t have the features you need or want. You’ll also need to determine the speed of scraping. A data collection service will also limit the number of queries you make per day. However, this service is reliable, and doesn’t require coding skills.
Using a data collection service to scrapify Google search is the easiest way to gather data from Google. They search hundreds of pages of Google results and provide you with relevant information for your project. You can choose a free trial of SERPMaster or opt to pay for a monthly subscription. You can get the data you need at no cost with SERPMaster. You can also make as many requests as you want for a trial version of the service.
There are thousands of tools available to scrape Google. Most of these tools are SEO tools. These services track page performance in SERPs and collect data on pages. Popular examples include Ahrefs, SEMrush, and Searchmetrics. If you’re looking for a fast, easy way to scrape Google, these extensions are perfect for you. There’s only one catch: you have to install them in your browser.
Using a visual web scraper
If you have extensive knowledge of JavaScript and web design, you can use a visual web scraper to automate Google’s search result page data. While most visual web scrapers are standalone programs, you may find that they struggle to process non-standard webpage structure. If you do not have much knowledge of JavaScript, you can use a browser extension. Another good option is AnyPicker. This Chrome extension allows you to set web extraction rules by simply clicking. It also integrates with Google Sheets so you don’t have to spend time parsing and uploading data. This tool uses Nohodo to process data and save it to your computer. It can also automate processes over multiple links.
A visual web scraper is a good option for those who are new to web scraping. These tools offer a point-and-click interface that allows you to extract data from web pages without the hassle of writing code. You can also specify the number of results per page to scrape. After you have chosen your desired results, you can click the Start button. The data will be saved into a CSV or JSON file, and you can access it in the Dataset tab.
Although Google does not offer a simple interface, there are many options available for the most efficient and effective way to scrape Google search results. Octoparse is an excellent option for this. It allows you to scrape Google Maps, and has intelligent anti-scraping features. It also comes as a standalone software or as a cloud-based solution. Its visual scraping tool is easy to use and is available as installable software.
The main problem with scrapers is that they are too fast and scrape too many pages, resulting in a pattern of similar results. Humans, on the other hand, do not visit individual results, and scrapers do not do this. By scraping Google SERPs, you can identify potential hacker damages. A hacked website’s credentials may end up on the dark web where they can be sold for a price. Hackers may also install malware on your website and monetize it.
Using a browser extension
While scraping Google Search result pages may seem like an easy task, it is not. Several factors make the process prohibitively complicated. Luckily, there are a few tools out there that allow you to extract data from Google Search result pages and export it to a spreadsheet. In this article, we’ll look at how to use a browser extension to scrape Google Search result pages.
First, you’ll need to install a browser extension to scrape Google Search. A browser extension is simple to use and requires no coding knowledge. Once installed, the tool will download page elements from the web page. It also supports JS, pagination, and form filling. Once downloaded, you’ll be able to analyze the information in the pages with the search query. While browser extensions offer a straightforward interface, they have limitations. Depending on your needs, these extensions are not suitable for scraping dynamic content.
While using a browser extension is convenient, the data collection service has a limited number of requests per day, and you’ll need to spend a little to access the data. You can even try out SERPMaster for free before you decide to sign up. Its free trial allows you to make a few hundred requests before you have to pay. You can also try out SERPMaster to see how it works.
Another option is to scrape the People Also Ask box in Google’s SERPs. SERP Keyword Scraper can help you scrape the People Also Ask box. This tool lets you copy search keywords from the SERPs and paste them into a spreadsheet program. The resulting spreadsheet is clean and organized and contains the search features. It also allows you to scrape the results from websites in any country.
[Sample] How to Scrape Google SERPs with SERPMaster

By now, you’re probably asking how I scrape a Google search page? Well, here’s a quick tutorial. We will show you the simplest way to scrape data from a Google serve page.
The very first step of starting to use SERPMaster is signing up. Once you do that, you’ll receive an email with the authentication information, which will provide you access to the SERP API. As you can probably tell from our code.
We are using Curl, a handy text-based tool that runs in the terminal and allows transferring data over the internet. First, you’ll need to enter your username and access token into u parameter. You’ll receive those after signing up then. It’s time to specify Queue, which represents the query that you’ll be making. For this example, our search term is ‘hello world.‘
The last step of this query is to specify that you’re sending application JSON content. Here’s how the code should look for the keyword ‘hello world.‘ Remember that some systems like ours require escaping quotes with a backslash.
We’ve got results printed out in the terminal window. But you might not like the look of that. This is the raw HTML content. It’s messy and hard to read. Don’t worry, though SERPMaster allows you to pass search results. Let’s set the passed parameter to ‘true‘, and SERPMaster will structure the scraped Google page. Now we’ve got our results in JSON format. So that’s how you use it.
Price of SERPMaster
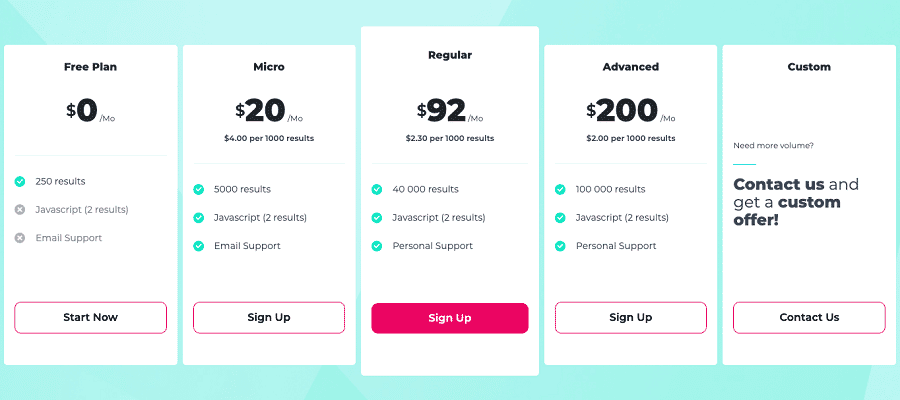
If you see that SERPMaster is exactly what you were looking for, the next thing you probably want to know is the price. Most scraping service providers charge higher prices. As a result, customers overspend and pay for the features they don’t even require. While SERPMaster offers budget-friendly data acquisition, so you don’t have to worry about overspending.
Is that really true?
Let’s crunch some numbers, so SERPMaster offers a variety of plans but no option to pay-as-you-go.
The smallest plan micro starts from just 20 per month and gives you 5 000 requests. This comes down to four dollars for 1 000 requests. The price per result is pretty high, but entry plans are never efficient. If you have 92 dollars per month to spare, then the price drops to 2.30 per 1000 results. Its biggest plan offers 100000 results for 200, which is two dollars for 1 000 results. And for those, who want to test things out first, SERPMaster offers a free trial with 250 results.
Now, let’s compare how its prices are fair against the competition. As you can see, SERPMaster sticks true to its claims. You must be thinking, if it’s so cheap, it has to cut corners in some way. Fair assumption. But surprisingly, that’s not really the case. SERPMaster is pretty rich in features. So let’s take a look at them.
Features of SERPMaster

First of all, SERPMaster can retrieve all data types from Google seriously. Here’s the list to prove it: organic paid or Twitter results. Everything you normally see on a SERP is there, and you can switch between mobile and desktop servers too. The targeting options are also impressive. The tool allows you to pick any country in the world. But if you need a little bit more precise targeting, then it also offers state and city-level results. You can even specify coordinates and radius.
SERPMaster isn’t a standalone point-and-click tool. So you’ll need to integrate it. The tool can handle three methods of integration.
The first one is called the browser. Where you send requests by forming long and complex URLs straight in your web browser’s address bar. It’s best suited for testing the tool.
The second is called real-time. Here you send post requests to SERPMaster over an open connection and receive data in well real-time.
The third method is called callback. Once again, you send a post request. Still, instead of retrieving results immediately, SERPMaster lets you fetch them whenever you wish. Usually, it’s done via webhooks. This method works best when you constantly need large amounts of data.
However, you can’t schedule searches, which SERPMaster competitors offer. With SERPMaster, you’ll be able to select which search results page to extract and how many entries it should include. But up to 100, all this data will be returned in raw HTML or past JSON formats. By the way, the JSON parser can handle most data types. Its output is neat and well structured. So you likely won’t need to clean up the data much now.
The User Experience of SERPMaster
We’ve discussed the features. Let’s talk about what it’s like to use SERPMaster.
Start using it. You’ll have to fill in the form and pay first. Then customer support will send you the credentials, allowing you to access the SERPMaster API. The process is the same for the free trial, except that you won’t have to pay for it.
When it comes to requests, SERPMaster accepts various parameters that allow specifying a keyword location device. And more you’ll need to write them by hand. But, it’s not that hard, even if you have a little coding experience. There are multiple APIs for specific types of search data, though they don’t differ much.
However, if you get confused about making requests specifying a query or anything else, the tool has detailed documentation that includes a walkthrough guide. The main drawback of this service is that there’s no dashboard or sandbox to play around with the tool. Everything is performed either via API or customer support.
The Customer Support of SERPMaster

Speaking of SERPMaster customer support, there’s no live chat. So don’t expect an ultra-fast response. However, the agents work 24 7, so they won’t keep you waiting forever. Remember that if you sign up for an entry plan, you’ll miss out on something SERPMastercalls personal support, basically calling your account manager directly instead of simply shooting emails.
Now let’s discuss performance. As we mentioned before, SERPMaster claims to provide a 100 success rate. We tested it to find out whether that’s true. We sent 10 requests per second to various Google URLs for the Albert test, which resulted in 100 000 requests with a timeout of 30 seconds, 95.7 of the request connected. To SERPMaster API, out of those requests, 100 successfully reached Google, which is a terrific result.
Conclusion
To sum up, I’ve just said SERPMaster is a low-cost, fast, and relatively simple way to scrape Google search results. It has various features, and its customer support shouldn’t let you down. Although there are three things, SERPMaster could include CSV, output request scheduling, and API playground. All in all, SERPMaster does what it promises and does it well.
If you need moderate amounts of data from Google and don’t want to build the web scraping infrastructure yourself, then consider SERPMaster. It’s a great option. Hope this article answered some of your questions about SERPMaster and helped you get started using it.
Source: Security Feed